
Esto es Andrea.
Cómo construí un sistema que le hace a marketing lo que la ingeniería ya le hizo a las fábricas — y por qué funciona. Desde Santiago.


En la universidad, hubo un curso que me voló la cabeza: Simulación.
A modo de introducción para los que no son del rubro: hay procesos en el mundo real que por su complejidad no se pueden modelar de una. Filas en supermercados, tráfico de una ciudad, una mina operando entera, una enfermedad propagándose por una población. Demasiadas piezas moviéndose al mismo tiempo y demasiado azar de por medio como para escribir una fórmula cerrada. Lo que sí se puede hacer es describir cada pieza por separado — cuántos clientes llegan en promedio, qué tan rápido atiende cada caja, cuánto demora cada camión — y dejar que el computador corra el sistema completo miles de veces. Lo que sale es la respuesta. Uno no la calcula, la ve aparecer. El simulador es, en el fondo, una “máquina del tiempo” que genera historia sintética.
Aprendí Simio. Aprendí Arena. Aprendí la matemática de cómo se modela un proceso. Y hay algo perversamente satisfactorio en correr mil escenarios y poder llegar a saber cuánto van a esperar los clientes, de que largo promedio va a ser la fila, cuándo va a fallar tal o cuál cosa, y ver empírica y teóricamente qué puede salir mal antes de que la empresa lo pague.
Los que han jugado Sims, SimCity, RollerCoaster Tycoon o Football Manager saben de qué hablo. (Fun fact: el primer proyecto comercial de Demis Hassabis — fundador de DeepMind, el de AlphaGo y AlphaFold — fue Theme Park, un sim de manejar parques de diversiones, a los 17 años. Antes de la AI, simulaba.)
Mientras tanto, en marketing — donde paso la mitad de mi vida profesional — no se simula nada. Y eso se nota.
Quién no ha escuchado el clásico, ya casi cliché a este punto: “la mitad del dinero que gasto en publicidad está perdido — el problema es que no sé cuál mitad.” Hoy, en 2026, con cookies muertas, atribución desmantelada por iOS, y plataformas que se auto-reportan el ROAS a su favor, el problema ya ni siquiera es que la mitad esté perdida. Es que nadie sabe — con seriedad — qué fracción del gasto está perdida, dónde, ni por qué. Se redistribuyen presupuestos millonarios entre Meta y Google todos los lunes según métricas que cada plataforma calcula con un sesgo conveniente. Y río arriba del gasto, las decisiones que lo generan — la creatividad, el targeting, el mensaje — se toman con todavía menos rigor.
La industria del marketing en LatAm — y, francamente, en todas partes — termina gastando miles de millones todos los años en base a intuición, o a métricas imprecisas y sesgadas que son un mero espejismo de rigurosidad.
Si conté esta historia más o menos bien, lo que sigue es obvio:
¿Qué pasa si le hago a marketing lo que la ingeniería ya le hizo a las fábricas? Modelar al consumidor. Simular el resultado. Atribuir el gasto con honestidad. Optimizar antes de quemar el presupuesto.
Eso es precisamente lo que hice. El proyecto se llama Andrea por mi mujer. Es un homenaje a ella ya que es una crack del marketing.
Me moví rápido. En un par de días tuve un MVP. Hoy, apenas un par de meses después, ya tengo algo que está bien cool: corre simulaciones de mercado a escala poblacional para que la decisión se tome antes de gastar, audita creatividades contra benchmarks de efectividad publicitaria, atribuye gasto a resultados con física bayesiana en vez de creerle a las plataformas, ejecuta medios con seis agentes autónomos, y publica su propio error contra benchmarks reales. Ocho marcas adentro.
En marzo, durante un evento comercial digital tipo Black Friday, subí una de las creatividades de la campaña al auditor del sistema. Le puso 42 sobre 100. Y me dijo, sin diplomacia, dos cosas concretas: faltaba emoción humana en el marco visual, y el bloque de motivación de compra estaba enterrado abajo, compitiendo con la oferta principal. Con eso, el sistema generó las dos variantes que sugirió. Las dos superaron al original. Le pasamos ese feedback — direccional y visual — al equipo creativo, que cerró las artes finales. Re-auditoría: 72.
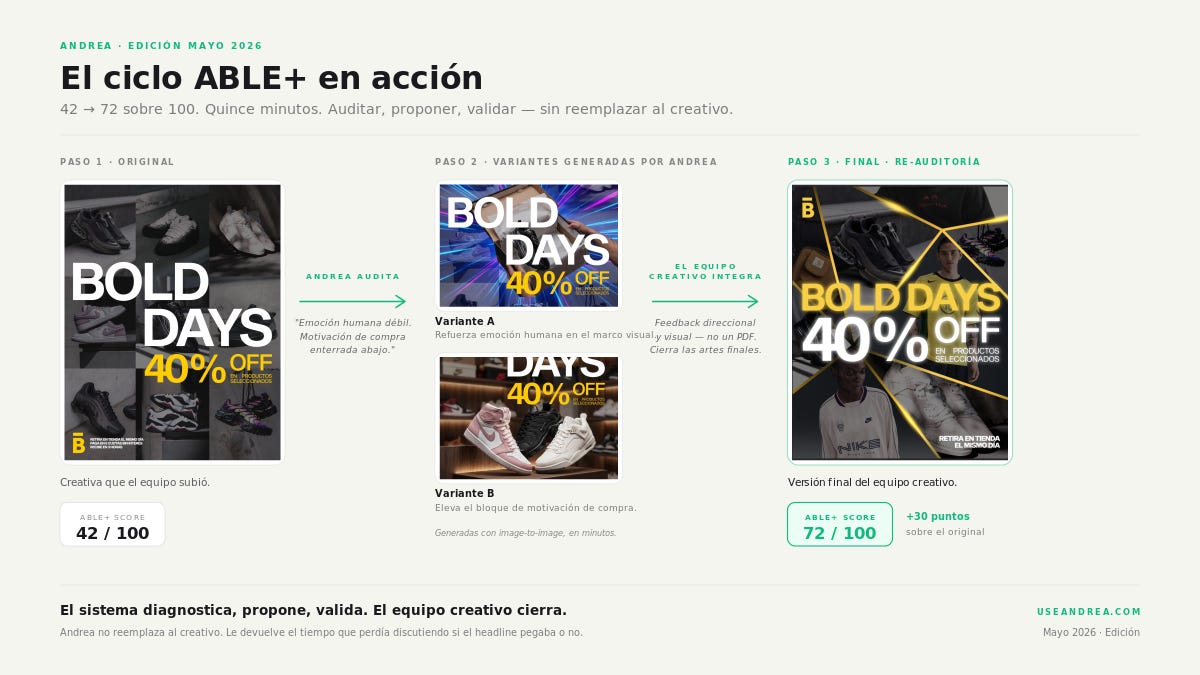
Treinta puntos arriba. Todo eso corrió en useandrea.com. Y dentro de las cinco cosas que el sistema hace, esta es la menos interesante. Las otras cuatro están corriendo, en este momento, para ocho marcas en producción — y me tiene muy emocionado: siento que estoy construyendo algo realmente innovador.
Antes de seguir: el ancla filosófica
Que quede claro antes de meternos en lo técnico. Andrea no reemplaza al creativo, ni al estratega, ni al analista, ni al planner de medios. Esto va por otro lado.
Los modelos de AI (LLM), al día de hoy, no son creativos por construcción. Son, simplificando un poco, interpoladores estadísticos extraordinariamente buenos sobre lo que ya existe. Eso podría cambiar — la frontera del modelado se mueve rápido y no es una afirmación que vaya a defender por los próximos cinco años — pero, al menos por ahora, eso es lo que tenemos y eso es lo que un LLM hace bien. No es bueno ni malo: es importante entender la herramienta para usarla bien.
Y resulta que ese perfil — interpolador estadístico afinado sobre el corpus acumulado de efectividad publicitaria, dinámicas sociales, comportamiento de consumo — es exactamente la herramienta correcta para auditar, calibrar, simular y proyectar. No para crear. La creatividad de la campaña la sigue haciendo el equipo de la marca, o la agencia, o quien tenga el criterio. Lo que el sistema hace es devolverle a esa gente la velocidad — el tiempo que se les iba en discusiones de Slack sobre si el headline pegaba o no, para que lo usen en lo que sí requiere criterio humano: decidir.
Esa es la regla con la que está construido todo lo que viene abajo.
Cinco cosas que hace Andrea hoy
1. Una sociedad sintética a escala — Society Twin
Lo más ambicioso del sistema. Una simulación chilena sintética de 100.000 personas, donde cada agente tiene una persona individual: edad, GSE, comuna, rasgos psicológicos. La movilidad entre comunas, las redes de adopción social, las dinámicas de propagación de opinión, las plataformas digitales — todo modelado con las matemáticas correctas, las que vienen de cuarenta años de literatura en sistemas complejos.
Lo único de Andrea, y lo que llamo internamente “el moat”, es que cada uno de esos 100.000 agentes puede reaccionar de forma personalizada a una creatividad específica. No todos reaccionan igual: la Carolina de Maipú con dos hijos chicos lee una campaña distinto a la Isidora de Providencia que vive de TikTok. Esa heterogeneidad es la pregunta que un CMO real quiere contestar: ¿por qué no funcionó esta campaña — y para quién sí?
Esto no es “una persona con LLM respondiendo preguntas”. Es una sociedad sintética que se ejecuta entera, en producción.
2. Profundidad cualitativa con física de grupo — Focus Group SOTA
Mi parte favorita del sistema. Un grupo focal sintético no debería ser “una persona con LLM que responde preguntas”. Eso es un chatbot disfrazado. Un grupo focal real tiene física de grupo: gente que opina distinto en privado y en público, gente que se conforma con la mayoría, gente que se diferencia para mantener identidad, un moderador que sonda más allá de la respuesta superficial, una dinámica que evoluciona durante la sesión.
Cada uno de esos comportamientos rompe a un grupo focal sintético naïve. La conformidad colapsa la diversidad de opiniones hasta la media — pierdes exactamente las voces marginales que más vale la pena escuchar. La ausencia de un modelo privado/público te entrega lo que la gente dice en una mesa con desconocidos, no lo que realmente piensa. Sin un crítico que desafíe el consenso, la conversación se vuelve eco. Sin profundizar, las respuestas son marketing-copy, no insight. Cada uno de esos problemas tiene una solución concreta, y todas viven dentro del sistema.
El output habla mejor que cualquier descripción del método. Acá una muestra real de un grupo focal sobre el nuevo flagship renovado de Belsport — la conversación corrió en quince minutos:
Isidora P., 22, Gen Z trendsetter: “Es como la Falabella del calzado, renovada, pero sigue siendo Falabella.”
Tomás A., 29, digital native: “El diseño es bonito, sí, pero mi billetera y mi lógica de optimización de compra son más fuertes que cualquier estética.”
Carolina M., 34, mamá práctica: “Que se vea así no me hace pensar automáticamente en ‘ofertas’ o ‘buenos precios’, sino más bien en ‘lo exclusivo’.”
Patricia M., 52, Gen X brand-loyal: “No es mi mundo, la verdad.”
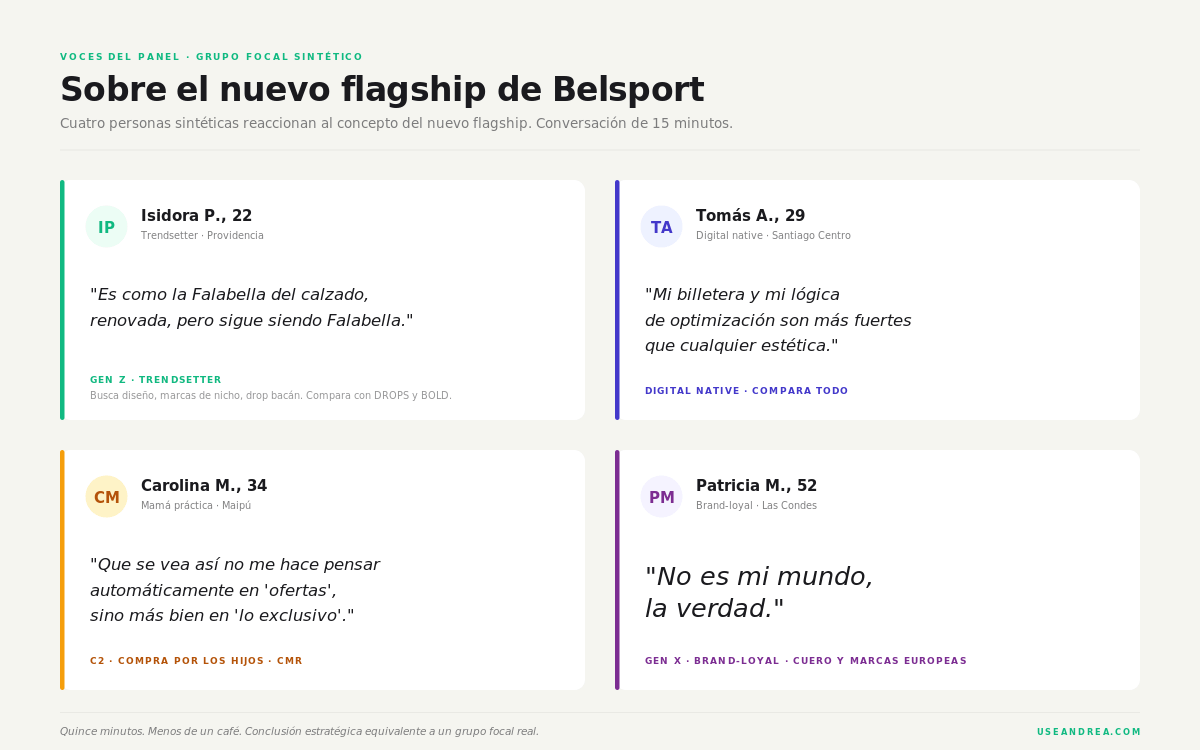
El moderador siguió preguntando qué les gustaría ver desde afuera para saber que la tienda renovada no había subido los precios. El panel — independientemente de la persona — convergió en tres señales: ofertas visibles desde la vitrina, asesoría destacada, variedad para todos los bolsillos. Esa es exactamente la decisión estratégica que un retailer toma con un grupo focal de tres semanas y treinta mil dólares. Acá fueron quince minutos.
3. Auditoría creativa con loop de mejora — ABLE+
Lo que vimos arriba con BOLD. ABLE+ es el sistema de auditoría creativa de Andrea. Lo importante no es la rubrica en sí — la rubrica de auditoría creativa existen hace décadas; los hay buenos y los hay menos buenos. Lo que hace distinto a ABLE+ es que la rubrica se adapta al contexto del estudio: la marca, el canal, el formato, el evento comercial, y sobre todo el público objetivo.
Una creatividad para Bold Days dirigida a Gen Z en TikTok no se audita con los mismos criterios que una pieza de Belsport para hombres de 45+ en Facebook. Una pieza de Black Friday para una marca de retail tiene otras prioridades que una pieza institucional. El sistema entiende el contexto y se ajusta: qué dimensiones pesan más, qué referencias usa como benchmark, qué tipo de feedback genera. El ciclo es completo: subes la pieza, el sistema la audita en su contexto específico, identifica los puntos débiles, genera variantes con image-to-image, y re-audita las variantes para confirmar el lift.
La pieza de BOLD entró con 42. Después de dos iteraciones del sistema acompañando al equipo creativo, salió con 72.
4. Física bayesiana del medio + seis agentes ejecutando — sobre el simulador
La parte que paga las cuentas, y donde se conecta el resto del sistema.
La capa de medios de Andrea hace dos cosas que se entrelazan. Primero, modela el retorno del gasto en cada canal con física bayesiana — atribuyendo de verdad, no creyéndole a las plataformas. Segundo, deja que seis agentes autónomos ejecuten encima de ese modelo, dentro de los límites que defina el equipo de marketing: monitorear anomalías, reasignar presupuesto, generar briefs creativos, orquestar entre canales, diagnosticar fricción de funnel, proponer hipótesis priorizadas.
Pero acá está la pieza que la hace única, y donde se cierra el círculo con todo lo anterior: los agentes no operan en el vacío. Operan sobre la simulación. El Society Twin genera la prior — qué reacción espera el modelo del mercado ante una campaña dada, antes de que la campaña se prenda. La capa de atribución bayesiana captura el resultado real — qué pasó, una vez que prendió. La distancia entre los dos es la señal que los agentes leen para decidir qué hacer. Y todo eso alimenta el último componente, que es donde el sistema se hace honesto consigo mismo.
5. Loop de calibración como pieza estructural
Lo que casi nadie hace en este espacio: publicar el error.
Casi todo el research sintético se vende con el discurso “es como un panel real, pero más rápido y más barato”. Lo que casi nadie dice es cuánto se desvía del panel real. Esa omisión no es accidental — un MAE público es la conversación más incómoda que un proveedor de research puede tener con un cliente, y es la conversación que casi nadie quiere tener.
Andrea la tiene. Por construcción. Hay dos razones para hacerlo así, y las dos son estructurales.
Primero, sin un error medido y publicado, no hay forma de mejorar. No hay manera de saber qué dimensiones del modelo están bien calibradas y cuáles tienen sesgos sistemáticos. Es exactamente lo que la ingeniería resolvió hace décadas: un proceso solo se optimiza cuando se mide. La calibración no es un nice-to-have, es la condición que separa un sistema que mejora con el tiempo de uno que se estanca el día que sale a producción.
Segundo, sin un error publicado, no hay confianza posible. Si yo te digo “esta predicción es buena” sin mostrarte qué tan bien predigo en general, te estoy pidiendo fe ciega. Eso no es research, eso es astrología con dashboards. Un cliente sofisticado quiere ver el error, quiere saber dónde el sistema funciona bien y dónde todavía no, quiere poder decidir cuánto pesa cada output según el tipo de decisión que está tomando.
Andrea publica su error contra benchmarks reales. La página vive en useandrea.com/validation, y se actualiza cuando hay un cambio material en el modelo.
La audiencia que la investigación de mercado clásica no puede levantar
Una cosa más antes de los momentos. Algo que me llevó un rato entender en toda su dimensión, y que probablemente sea la consecuencia más subestimada de todo lo de arriba.
Un panel real tiene un sesgo estructural que casi nadie discute en voz alta: solo participan los que pueden, quieren y se les permite participar. Suena obvio. Las implicancias no lo son. Hay tres grupos enteros de la economía que están sistemáticamente sub-representados en cualquier estudio cuantitativo o cualitativo, y los tres son comercialmente enormes.
Los que deciden, pero no contestan encuestas. CEOs, CFOs, directores médicos, gerentes generales, jefes de compras industriales, socios de firmas de abogados. La gente que firma cheques de seis y siete cifras al mes no se sienta en un grupo focal de dos horas en una sala de Providencia, ni contesta una encuesta online por veinte mil pesos de incentivo. Y, sin embargo, son exactamente las personas que un proveedor B2B necesita entender — porque son los compradores. El research B2B serio es uno de los problemas más caros y peor resueltos de la industria. Cobran $50–80K USD por veinte entrevistas en profundidad con C-suite y la mitad de las veces ni siquiera consiguen completar la muestra.
Los que son demasiado jóvenes para participar legalmente. Menores de catorce, de doce, de ocho. Una marca de juguetes, de útiles escolares, de cereales, de contenido digital infantil, de comida rápida-familiar — toda tiene como cliente final a un menor de edad. Pero el research formal con menores requiere consentimiento parental, aprobación ética, protocolos de protección reforzados. La consecuencia, casi siempre: la marca termina entrevistando a la mamá, no al niño. Una capa de proxy entre la decisión real y la pregunta que se formula.
Los que son demasiado mayores para que la industria los priorice. Los mayores de 75 ya no son target objetivo de la mayoría de las marcas, así que el sistema de research los descarta por defecto. Pero la pirámide demográfica se está invirtiendo en todas partes — en Chile, en el resto de LatAm, en todo el mundo desarrollado. En 2040, uno de cada cuatro chilenos va a tener sobre 65. Farma, seguros, retail de salud, banca para jubilación, turismo senior, real estate adaptado, servicios funerarios, telemedicina — todas las industrias que dependen de esa pirámide van a necesitar entender a un consumidor que el research actual literalmente no levanta.
Andrea simula a los tres. Si la persona existe — o podría existir — se puede modelar con la misma profundidad psicológica, demográfica y conductual que cualquier otra. No requiere panel real, no requiere reclutamiento, no requiere protocolos éticos especiales porque el sujeto es sintético. Para B2B, “imposible hacer fieldwork con CEOs” se convierte en “un panel de cincuenta CFOs sintéticos en industria manufacturera contesta tu cuestionario en quince minutos.” Para silver economy, lo mismo. Para investigación con menores, lo mismo.
Esto no reemplaza los pocos estudios reales que sí se hacen con esos segmentos cuando hay presupuesto y tiempo. Los reemplaza para todo lo demás: iteración de hipótesis, bench-testing de positioning, screening de creatividades antes de comprometer el (muy caro y muy lento) estudio real con un panel humano de C-suite, o de pacientes oncológicos, o de adolescentes, o de personas con discapacidad visual.
Es por esto, también, que los próximos sectores donde el sistema va a hacer la diferencia más visible son los que dependen de audiencias que la investigación tradicional nunca pudo alcanzar.
Tres momentos que ya pasaron
Momento uno — el sistema vs un estudio cuantitativo publicado
Tomé un estudio cuantitativo publicado del mercado chileno de zapatillas, hecho con consumidores reales estratificados por edad, género, GSE y región. El estudio reporta siete columnas de funnel para nueve marcas — sesenta y tres celdas en total — más drivers, atributos y ad recall.
Le pedí a Andrea correr el mismo estudio, contra el mismo set competitivo, con el mismo cuestionario.
El criterio de precisión al que apunté viene de combinar la literatura sobre paneles sintéticos con nuestras propias mediciones internas: un panel sintético bien calibrado puede llegar dentro de 10-20 puntos porcentuales del estudio real para la mayoría de las celdas, con resultados materialmente mejores (sub-5pp) en las métricas de adopción y compra que más le importan al cliente. Más preciso que eso, y normalmente estás mirando ruido estocástico del propio panel real. Más impreciso, y estás perdiendo la información direccional.
Andrea entregó dentro de ese rango. Las métricas de adopción y compra para la marca focal cayeron dentro de ±2-3 puntos del estudio real. El 40% de las celdas totales quedaron dentro de 10 puntos. Las marcas nicho matchearon con 5-11 puntos. La excepción conocida: el conocimiento de marcas grandes se sobreestima — no es un problema del modelo, es un patrón de los LLMs sobre listas de marcas conocidas, y ya tiene una solución técnica en producción.
Un estudio cuantitativo de ese alcance cuesta normalmente entre $50.000 y $150.000 y toma seis a doce semanas. Andrea corre en 25 minutos.

La lectura honesta: Andrea todavía no es un sustituto de un estudio cuantitativo cuando necesitas accuracy a nivel de celda para reportería regulatoria. Sí es un sustituto para iteración rápida sobre el cuestionario antes de comprometer el estudio real, lectura direccional para estrategia, generación de hipótesis, tracking entre olas de fieldwork real, o bench-testing de hipótesis de posicionamiento.
Momento dos — un grupo focal sintético sobre el nuevo flagship
El que ya vimos arriba, con Isidora, Tomás, Carolina y Patricia. Quince minutos de conversación, menos de un café, un panel diverso de seis personas sintéticas reaccionando al concepto del flagship renovado de Belsport. La conclusión estratégica del moderador — el panel converge en que la tienda renovada necesita comunicar “ofertas visibles + asesoría destacada + variedad para todos los bolsillos” desde la vitrina si no quiere ahuyentar a la mamá práctica y al digital native — es la misma conclusión que sale de un grupo focal real, salvo que el real toma tres semanas y cuesta entre veinte y treinta mil dólares.
La pieza importante: las cuatro reacciones reflejan personas distintas, con prioridades distintas, con voz distinta. Isidora habla en idioma TikTok-ese. Patricia menciona Tod’s y Ferragamo sin pedir disculpas. Tomás compara precios con Miami. Carolina piensa en sus dos hijos chicos antes que en sí misma. Eso es la heterogeneidad que un focus group está diseñado para capturar — y que los grupos focales sintéticos genéricos pierden cuando todas las “personas” terminan sonando igual.
Momento tres — el simulador vs una adopción real publicada
El simulador del Society Twin no es un experimento mental. Lo entrené contra adopción real publicada de una campaña a escala nacional, en 19 segmentos demográficos y regionales. Las dos curvas centrales — las que más importan para confiar en la dinámica del modelo — matchean al benchmark real dentro de dos puntos porcentuales. El MAE agregado sobre las 19 dimensiones es 5,16 puntos.
Para contexto: la literatura de simulación de agentes generativos reporta MAE típicos entre 8 y 15 puntos para modelos no-LLM, y entre 4 y 10 para los mejores modelos LLM publicados. Andrea queda dentro del rango competitivo top, sobre un dominio donde los datos reales son auditables.
El proceso es determinístico — mismo input produce exactamente mismo output — y reproducible para cualquier auditor. Eso no es lo común. Lo común en este espacio es: “corre, ¿confías en mí?”.
Por qué esto funciona
Cada decisión arquitectónica del sistema está basada en literatura científica peer-reviewed publicada en los últimos tres años. Cómo se generan personas sintéticas sin que colapsen a la media optimista. Cómo se modela una dinámica de opinión que no degenere en eco. Cómo se evita el sesgo sistemático de los LLMs hacia respuestas socialmente deseables. Cómo se mide la diversidad real de salida en un sistema generativo. Cómo se calibra atribución de medios cuando los datos están sesgados por la plataforma reportante.
Pasé meses leyendo esa literatura — papers de Stanford, de Harvard Business School, de revistas peer-reviewed de física aplicada y ciencias del comportamiento — y cada decisión de diseño en Andrea está documentada con la cita que la sostiene. La bibliografía completa, con punteros al código exacto que cada paper informó, vive en useandrea.com/research. Si a algún lector le interesa esta parte más académica, encantado de ir por un café y mostrarles todo.
Lo que sí voy a decir, porque es estructural: Andrea es agnóstica al modelo. La capa de inferencia puede correr sobre cualquier proveedor de frontera — Gemini, Claude, GPT, los que vengan de aquí a cinco años. Y dentro del sistema hay una capa de calibración entre modelos que normaliza output cuando se cambia de proveedor — porque los sesgos sistemáticos de un modelo no son los de otro, y un sistema que solo funciona con un proveedor específico es frágil por construcción. La capa de calibración es lo que permite que el modelo cambie sin que el cliente lo note.
Por qué ahora
Tres cosas que hace dos años no existían, hoy corriendo todas juntas.
Primero, economía de inferencia razonable. Los modelos de frontera bajaron de precio dos órdenes de magnitud en los últimos veinticuatro meses. Un panel sintético de cien personas cuesta hoy lo que costaba un solo prompt hace dos años. Hace cinco años, ni con un orden de magnitud más de presupuesto era posible.
Segundo, MMM open-source. Lo que antes era un servicio de consultora a $200.000 al año, ahora corre como librería en cualquier servidor. La capa de atribución bayesiana de Andrea apoya buena parte de su validación cruzada en herramientas que recién en los últimos doce meses se volvieron accesibles.
Tercero, frameworks agénticos en producción. Los seis agentes que ejecutan medios dentro de Andrea no eran construibles hace dieciocho meses sin plumbing custom que se llevaba más tiempo que el modelo en sí. Ahora son librería estándar.
Y, por arriba, la atribución web colapsó: iOS rompió el pixel, las cookies de tercera parte se mueren, las plataformas se auto-reportan el ROAS con sesgo. La distancia entre lo que se puede hacer hoy con inferencia barata y lo que se está haciendo es enorme.
Lo que viene
Esta es la edición de mayo. Lo que está corriendo hoy ya no entra en este post — me quedaron afuera cosas que voy a contar en las próximas ediciones. La validación del simulador contra verticales comerciales, no solo de adopción pública. El loop de calibración corriendo en vivo sobre campañas reales en Meta y Google. Los primeros brand-health trackers continuos que arrancan en julio, donde el estudio se repite todos los meses contra el mismo panel y se ve derivar la marca en el tiempo. La integración con agencias para que sus equipos creativos usen el auditor sin tener que pasar por la plataforma completa.
Estoy en conversaciones con un número limitado de marcas que quieren ser early-design partners en lo próximo. Los espacios se están llenando rápido. Si te interesa para tu marca, o para una marca que asesoras, no esperes a la próxima edición.
Si quieres saber más sobre esto y su potencial, escríbeme. La conversación es lo que decide.
— Sebastian Gebhardt R · Mayo 2026
